

Insensibile al non eccelso numero di visite ottenuto dal primo articolo di questa serie (Vogliamo davvero un’Intelligenza Artificiale “spiegabile”?), proseguo imperterrito con questo secondo, in cui vorrei sintetizzare quello che da un punto di vista legale e normativo è già stato fatto in materia e quello che si annuncia per il prossimo futuro.
Per farlo, devo necessariamente avventurarmi su un terreno giuridico, a me non particolarmente confacente, e quindi gli specialisti dovranno mettere in conto una certa quota di imprecisione; d’altra parte, mi azzardo a predire che i vincoli legali che le applicazioni di Intelligenza Artificiale (IA, o più spesso AI) avranno, o non avranno, saranno decisivi per la vita di tutti noi, e quindi da cittadini non possiamo disinteressarcene. Questo è il motivo per cui ho deciso di scriverne, e non c’è dubbio che sarei felicissimo di ricevere contributi anche critici di chi di legge capisce e sa più di me.
Dopo questa classica excusatio non petita, veniamo alla sostanza, e proviamo a enunciare il problema di base a cui ci troviamo di fronte (per un’illustrazione più ampia rinvio al precedente articolo già citato). Esistono alcuni campi di applicazione “sensibili”, o ad alto rischio, nei quali le tecnologie di AI possono da un lato essere preziose (già oggi, e sempre più nel futuro, l’AI è ad esempio fondamentale nell’analisi delle immagini prodotte da TAC e risonanze magnetiche, come spiega ad esempio questo articolo su TIME), dall’altro ridurre la capacità umana di controllare e comprendere le diagnosi. Come abbiamo visto in precedenza, alcune tra le tecniche di AI più efficaci sono in realtà delle black box, e non consentono neanche ai progettisti SW di comprendere perché, ad esempio, da una TAC si ottenga una diagnosi di tumore. Dato che per molti una decisione senza spiegazione non è accettabile, ci sono numerose iniziative anche legislative intese a garantire che, specie per le applicazioni ad alto rischio, si possa sempre ottenere una spiegazione, o integrando il “responso” dell’AI con informazioni accessorie che consentano ex post di ricostruire almeno in parte i razionali del responso stesso (Explainable AI), o evitando del tutto le tecnologie AI che producono delle black box e utilizzando invece tecnologie che usino algoritmi intrinsecamente più trasparenti e comprensibili (Interpretable AI). Vediamo quindi a che punto sono queste iniziative.
Oggi, un primo livello di tutela è offerto dal GDPR, la ben nota legge europea sulla protezione dei dati personali. Esso, nell’articolo 22, afferma che ogni cittadino dell’UE ha «il diritto di non essere sottoposto a una decisione basata unicamente sul trattamento automatizzato, compresa la profilazione, che produca effetti giuridici che lo riguardano o che incida in modo analogo significativamente sulla sua persona» (qui e nel seguito i grassetti sono miei); nel precedente articolo 15, il testo afferma che nel caso che un simile trattamento automatizzato venga applicato, chi ne è oggetto ha diritto a ricevere «informazioni significative sulla logica utilizzata, nonché l’importanza e le conseguenze previste di tale trattamento per l’interessato». Una discussione più ampia sulle implicazioni di questi articoli è svolta nel Considerando 71 (che non è parte del testo legalmente vincolante), secondo cui «tale trattamento dovrebbe essere subordinato a garanzie adeguate, che dovrebbero comprendere la specifica informazione all’interessato e il diritto di ottenere l’intervento umano, di esprimere la propria opinione, di ottenere una spiegazione della decisione conseguita dopo tale valutazione e di contestare la decisione».
Una normativa analoga è contenuta nella cosiddetta Convenzione 108+ del Consiglio d’Europa, che, tra le altre disposizioni, all’Articolo 9 prevede per l’interessato il diritto «di ottenere, su richiesta, informazioni sulla logica sottostante il trattamento dei dati nei casi in cui i risultati di tale trattamento gli siano applicati» (la traduzione dal testo in inglese è mia). L’importanza di questa Convenzione sta nel fatto di essere applicabile a qualsiasi soggetto pubblico o privato che acquisisca dati personali (non solo le aziende quindi, ma anche le autorità statali) e di essere stata sottoscritta da 45 paesi, inclusi diversi non appartenenti al Consiglio d’Europa stesso, e quindi di rappresentare una base giuridica più estesa del GDPR.
Senza entrare in un’analisi strettamente giuridica (chi è interessato può trovarne diverse in rete, ad esempio qui), queste tutele, se da un lato a rigore non hanno grandi implicazioni sulle situazioni concretamente esistenti (non esiste praticamente nessuna applicazione AI che comporti decisioni critiche sulle persone che non prevedano una supervisione umana di qualche tipo, e comunque il testo legalmente vincolante del GDPR non afferma di per sé un vero «diritto alla spiegazione»), dall’altro indicano chiaramente una linea di principio, secondo cui le persone dovrebbero poter conoscere, capire ed eventualmente contestare la logica delle decisioni che li riguardano, che siano prese da esseri umani o da sistemi AI. Ed è chiaro che è praticamente impossibile contestare una decisione presa da una black box senza alcuna spiegazione: come si contesta un «perché sì»? Insomma: se il diritto alla spiegazione non è imposto dalla lettera del GDPR o della Convenzione 108+, a mio avviso è parte dello spirito della normativa.
Domani, il trattamento dei dati effettuato da sistemi AI sarà con ogni probabilità regolato dall’AI Act, una normativa ancora in via di elaborazione e che dichiara i propri scopi come (il testo in italiano è disponibile qui):
- assicurare che i sistemi di IA immessi sul mercato dell’Unione e utilizzati siano sicuri e rispettino la normativa vigente in materia di diritti fondamentali e i valori dell’Unione;
- assicurare la certezza del diritto per facilitare gli investimenti e l’innovazione nell’intelligenza artificiale;
- migliorare la governance e l’applicazione effettiva della normativa esistente in materia di diritti fondamentali e requisiti di sicurezza applicabili ai sistemi di IA;
- facilitare lo sviluppo di un mercato unico per applicazioni di IA lecite, sicure e affidabili nonché prevenire la frammentazione del mercato.
In realtà, già definire un sistema di AI non è una cosa facile. L’AI Act essenzialmente identifica i sistemi di AI come quelli sviluppati utilizzando determinati approcci o tecniche per produrre contenuti, raccomandazioni o decisioni. Una volta stabilito, sia pure in modo francamente poco soddisfacente, cosa siano i sistemi di AI, il testo li classifica in quattro categorie in funzione del rischio a essi associato, come si vede in questa immagine tratta da una presentazione della Commissione Europea:
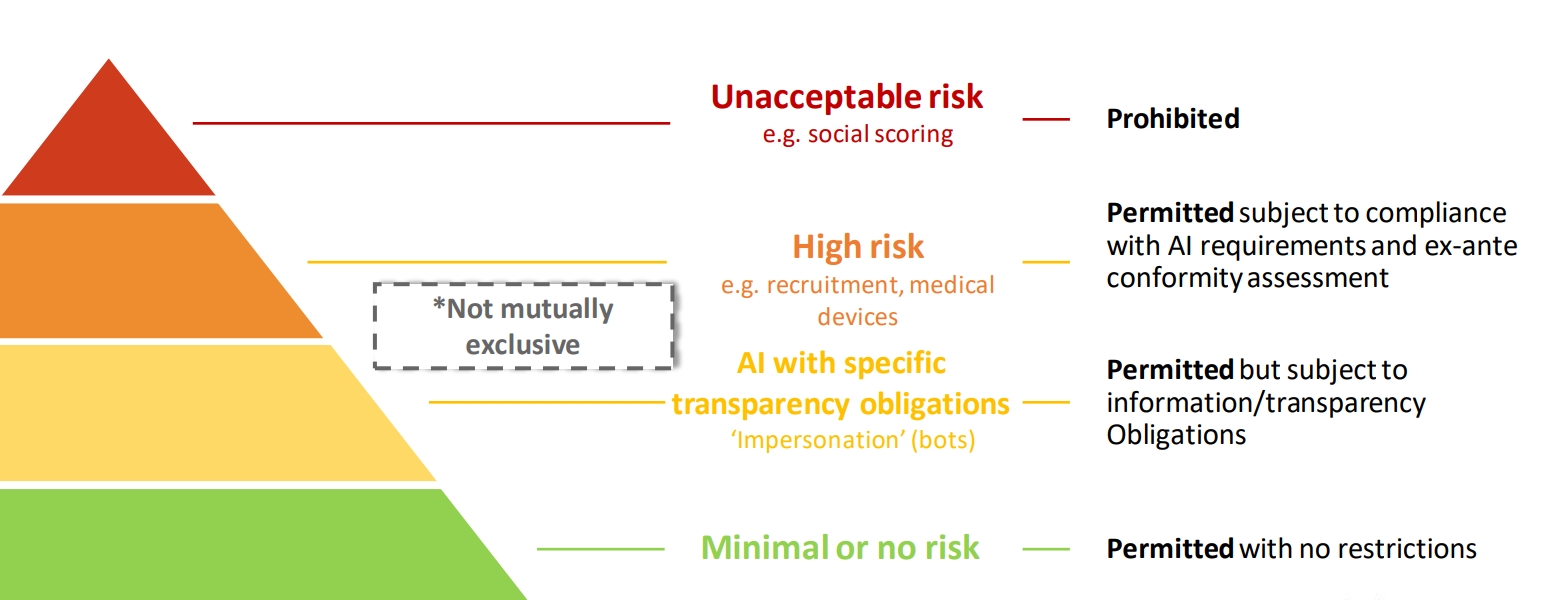
Le applicazioni il cui rischio è inaccettabile, e che saranno proibite, includono tra le altre quelle finalizzate alla manipolazione subliminale del comportamento, o i sistemi di social scoring “alla cinese”, ossia che attribuiscano ai cittadini penalizzazioni in funzione del loro comportamento sociale in modo «ingiustificato o sproporzionato». Le applicazioni a rischio basso o assente saranno esenti da restrizioni, mentre quelle a rischio alto, e/o che usano specifiche tecnologie soggette a speciali obblighi di trasparenza (ad esempio i tool per creare deep fake), sono in sostanza quelle per cui sono state pensate le prescrizioni dell’AI Act. Tra le numerose norme (tra cui alcune molto importanti relative ai dati, su cui forse meriterà tornare) figura l’obbligo di realizzare i sistemi in oggetto «in modo tale da garantire che il loro funzionamento sia sufficientemente trasparente da consentire agli utenti di interpretare l’output del sistema e utilizzarlo adeguatamente» (art. 13), e di mettere a disposizione degli utilizzatori di tali sistemi strumenti adeguati a permettere «di interpretare correttamente l’output del sistema di IA ad alto rischio, tenendo conto in particolare delle caratteristiche del sistema e degli strumenti e dei metodi di interpretazione disponibili» (art. 14).
La (mia) conclusione è che anche l’AI Act, senza imporre obblighi tassativi in merito, implichi auspicare per i sistemi ad alto rischio (elencati in uno degli allegati al testo) un approccio che preveda la spiegabilità dei loro risultati (Explainable AI, nel senso detto sopra), se non addirittura l’adozione delle sole tecniche intrinsecamente interpretabili (Interpretable AI).
E dopodomani? Il futuro più lontano ovviamente è ancora da scrivere, ma dobbiamo immaginare che “dopodomani” (che in un campo come questo significa tra pochi anni) ci troveremo di fronte a una tensione tra due esigenze, entrambe derivanti da un’applicazione molto più estensiva dei sistemi di AI a contesti vitali, come quello sanitario o quello della sicurezza: la necessità di proteggere i diritti individuali dei cittadini da scenari, ad esempio, alla Minority Report, e quella di offrire i servizi più efficaci possibile, sfruttando anche capacità dell’AI che possano superare quelle cognitive umane.
Alcuni addetti ai lavori (rimando ad esempio nuovamente all’articolo di Cynthia Rudin già citato in precedenza) auspicano che proprio in vista dell’estensione del “potere” dei sistemi AI vengano adottate norme più restrittive, per consentire agli esseri umani coinvolti nelle decisioni di comprenderne le ragioni, esprimere un consenso realmente informato, avanzare eventuali ricorsi, individuare eventuali distorsioni e pregiudizi (bias) incorporati nei meccanismi decisionali delle intelligenze artificiali. Queste posizioni di fatto auspicano che venga effettivamente e inequivocamente codificato un diritto alla spiegazione da parte dei cittadini (diritto che, secondo la mia comprensione e nonostante opinioni non unanimi, oggi non esiste), e che questo implichi l’obbligo di adottare solo tecniche di Interpretable AI. Un’esposizione sintetica delle ragioni a favore di questa ipotesi è proposta ad esempio dalla dottoressa Chiara Gallese in un intervento all’interno dei lavori dell’Information Society Law Center.
Spero di essere stato chiaro, e soprattutto di non aver dato l’impressione che questo argomento sia interessante solo per una manciata di specialisti di AI e di giurisprudenza, o peggio dell’intersezione tra le due discipline. Si tratta invece di qualcosa che riguarda tutti, e se oggi può sembrare poco importante, tra cinque anni lo sarà moltissimo; le soluzioni che adotteremo avranno effetti molto incisivi, sull’efficacia delle soluzioni AI, sulla loro controllabilità, sulla loro accettabilità e, in ultima analisi, sul nostro rapporto con i sistemi “intelligenti”.
Dopo aver presentato, in questo articolo e nel precedente, una fotografia per quanto potessi obiettiva della situazione, in un prossimo articolo proverò a proporre una mia visione del problema e delle scelte che considero desiderabili, evidenziandone i possibili vantaggi e svantaggi.
